2026年AI研究の最前線:マルチモーダル動画生成・効率的Transformer・数学的普遍演算子・マルチエージェント協調の統合的考察
動画生成AIの新パラダイム『OmniShow』、パラメータ効率を革新する『ELT』、数学の普遍演算子『EML』、そしてAnthropicが整理したマルチエージェント協調パターンという4つの最先端研究を横断的に読み解き、2026年春のAI研究潮流を専門家視点で深掘りする。
はじめに:2026年春、AI研究に走る4つの断層線
2026年4月、AI研究コミュニティは複数の異なる方向で同時に加速している。一方では動画生成モデルが「テキストだけ」という制約を超え、音声・姿勢・参照画像を統合した複合条件制御へと進化している。もう一方では、巨大モデルの「重さ」に対するアンチテーゼとして、パラメータ共有と反復計算によって効率性を根本から問い直すアーキテクチャ研究が台頭している。さらに純粋数学の領域では、すべての初等関数を単一演算子から導出できるという驚くべき発見が報告された。そして実用AIシステムの設計論として、マルチエージェント協調パターンの体系化が進んでいる。
これら4つの潮流は一見バラバラに見えるが、深く読むと共通する問いが浮かび上がる。「最小限の構成要素から最大限の表現力を引き出すにはどうすればよいか」という問いである。本稿ではこの視点を軸に、各研究を統合的に解説する。
OmniShow:マルチモーダル条件を統合した人物-物体インタラクション動画生成
タスク定義と産業的背景
香港中文大学とByteDanceの共同研究チームが発表した OmniShow は、Human-Object Interaction Video Generation(HOIVG)という新たなタスクを正式に定義し、そのエンドツーエンド解法を提示した論文である(
)。HOIVGが要求する入力は4種類ある。グローバルな意味を規定するテキストプロンプト、特定キャラクターや物体の外観を指定する参照画像、リップシンクや身体動作を駆動する音声、そして複雑な動きを明示的に制御するポーズシーケンスだ。これらを同時に扱えるフレームワークはこれまで存在しなかった。
実用的な需要は明確である。ECサイトの商品デモ動画、ショート動画コンテンツの自動生成、インタラクティブエンターテインメントなど、現実のコンテンツ制作現場では「特定の人物が特定の物体を持ち、特定の動きをしながら話す」という複合的な制御が不可欠だ。
 図1: OmniShowの全体像。R2V(参照画像→動画)、RA2V(参照画像+音声→動画)、RP2V(参照画像+ポーズ→動画)、そして最難関のRAP2V(全条件統合)まで、統一フレームワークで対応する。
図1: OmniShowの全体像。R2V(参照画像→動画)、RA2V(参照画像+音声→動画)、RP2V(参照画像+ポーズ→動画)、そして最難関のRAP2V(全条件統合)まで、統一フレームワークで対応する。
この図が示すように、OmniShowは単一モデルでこれら全ての条件設定に対応し、産業グレードの映像品質を維持する。
3つの技術的革新
① Unified Channel-wise Conditioning(統合チャネル方向条件付け)
既存の参照画像注入手法の多くは、クロスアテンションや追加のアダプタモジュールを用いるが、これはベースモデルの事前学習済み生成プライアを乱すリスクがある。OmniShowは「擬似フレームトークン(pseudo-frame tokens)」という概念を導入し、ノイズ付き動画トークンの時間次元に追加トークンをパディングする。ポーズ動画と参照画像はともにVAEでエンコードされ、同一のチャネル結合戦略で注入される。さらに擬似フレームに再構成損失を課すことで、参照画像の意味的詳細の保持を促進する。
 図3: 条件付け手法の定性的・定量的比較。提案手法は参照被写体の視覚的外観を正確に保持する。
図3: 条件付け手法の定性的・定量的比較。提案手法は参照被写体の視覚的外観を正確に保持する。
この設計の本質は「ベースモデルのネイティブ入力構造とトークン分布を維持する」点にある。アーキテクチャへの侵襲を最小化しながら効率的な注入を実現するという哲学は、後述するELTの「重み共有による効率化」と通底する発想だ。
② Gated Local-Context Attention(ゲート付き局所文脈アテンション)
音声-映像の同期は、単純なクロスアテンションでは達成困難だ。OmniShowは音声コンテクストパッキング戦略で豊富な音声特徴を集約し、マスクアテンション機構によって動画トークンが対応する音声セグメントのみと相互作用するよう制限する。さらに学習可能なゲーティングベクトルを導入し、学習初期の不安定性を抑制しつつ音声キューの影響度を明示的に制御する。
 図5: gベクトルの平均ノルムの変化。ブロックごとに音声が動画生成に与える影響の強さが異なることを示す。
図5: gベクトルの平均ノルムの変化。ブロックごとに音声が動画生成に与える影響の強さが異なることを示す。
③ Decoupled-Then-Joint Training(分離後統合学習)
HOIVGの最大の障壁の一つはデータ不足だ。音声・参照画像・ポーズを同時に含む「五重奏データ」は極めて希少である。OmniShowはこの問題を「分離後統合」戦略で解決する。まずA2V(音声→動画)とR2V(参照画像→動画)の専門モデルを個別に学習し、その後モデルマージングによって統合する。
 図4: RA2Vタスクで明示的に学習していないにもかかわらず、マージされたモデルは参照画像と音声の両方を尊重した動画を生成できる。
図4: RA2Vタスクで明示的に学習していないにもかかわらず、マージされたモデルは参照画像と音声の両方を尊重した動画を生成できる。
この「ゼロショット汎化」は特筆に値する。個別タスクで学習した能力が、マージ後に自然に組み合わさるという現象は、モデルの内部表現が何らかの共通構造を持つことを示唆している。
HOIVG-Bench:評価基準の確立
OmniShowはモデルだけでなく、HOIVG-Benchという専用ベンチマークも提供する。これはHOIVG研究の評価空間を標準化する重要な貢献だ。
 図6: テキストプロンプトのワードクラウドと動作強度分布。多様な人物-物体インタラクションシナリオと動的レンジをカバーする。
図6: テキストプロンプトのワードクラウドと動作強度分布。多様な人物-物体インタラクションシナリオと動的レンジをカバーする。
ELT:弾性ループTransformerによる視覚生成の効率化革命
DeepMindの研究チームが発表した Elastic Looped Transformers(ELT) は、視覚生成モデルのパラメータ効率を根本から問い直す(
)。
従来の生成モデルは、深いスタックの「ユニークなTransformerレイヤー」を積み重ねることで表現力を獲得してきた。ELTはこれに対し、重み共有された反復Transformerブロックを用いる。同じパラメータを繰り返し適用することで、パラメータ数を大幅に削減しながら高品質な生成を維持する。
核心的な技術革新は Intra-Loop Self Distillation(ILSD) だ。最大ループ数の設定を「教師」とし、中間ループ数の設定を「生徒」として蒸留を行う。これを単一の学習ステップ内で実施することで、モデルの深さ方向の一貫性を確保する。
結果として、ELTは単一の学習実行から弾性的なモデルファミリーを生成する。推論時にループ数を動的に調整することで、計算コストと生成品質のトレードオフをリアルタイムに制御できる「Any-Time推論」が実現する。
定量的成果は印象的だ。等価推論計算量の設定でパラメータ数を4倍削減しながら、クラス条件付きImageNet 256×256でFID 2.0、UCF-101でFVD 72.8を達成した。
OmniShowとELTを対比すると興味深い。OmniShowは「複数の条件を統合する複雑さ」に対し、アーキテクチャへの侵襲を最小化することで対処した。ELTは「モデルの深さ」という複雑さに対し、重み共有という根本的な単純化で対処した。両者は「最小限の構造変更で最大の効果を得る」という設計哲学を共有している。
EML演算子:連続数学における「NANDゲート」の発見
クラクフのヤギェウォ大学のAndrzej Odrzywołekが発表した研究は、AIとは一見無関係に見えるが、深い示唆を持つ(
)。デジタルエレクトロニクスでは、単一の2入力ゲート(NAND)があらゆるブール回路を構成できる。連続数学にはそのような普遍的プリミティブが存在しないとされてきた。本研究は、eml(x, y) = exp(x) − ln(y) という単一の二項演算子と定数1の組み合わせが、科学計算機の標準的な関数レパートリー全体を生成できることを示した。
具体的には:
e^x = eml(x, 1)ln(x) = eml(1, eml(eml(1, x), 1))- さらにsin、cos、√、π、iなど全ての初等関数と定数が導出可能
 図1: EMLを「最後の共通祖先(LUCA)」とした初等関数の系統発生的ツリー。螺旋は発見された順序に従って展開し、各関数がどの要素から構成されるかを矢印で示す。
図1: EMLを「最後の共通祖先(LUCA)」とした初等関数の系統発生的ツリー。螺旋は発見された順序に従って展開し、各関数がどの要素から構成されるかを矢印で示す。
この図が示すように、すべての初等関数はEMLという単一の「祖先」から派生する系統樹として表現できる。
EML表現の文法は驚くほど単純だ:S → 1 | eml(S, S)。これはカタラン構造や完全二分木と同型な文脈自由言語であり、すべての数式が同一ノードの二分木として表現される。
AIへの直接的な含意も大きい。EMLツリーは勾配ベースの記号回帰のための均一な探索空間を提供する。Adamオプティマイザを用いてEMLツリーをパラメータ化された回路として最適化すると、生成則が初等的である場合、数値データから閉形式の数式を正確に回復できることが実証された。
これはELTの「重み共有による均一構造」とも共鳴する。ELTが同一のTransformerブロックを繰り返すことで複雑な視覚表現を生成するように、EMLは同一の演算子を再帰的に組み合わせることで複雑な数学的表現を生成する。「均一な構成要素の反復」という原理が、全く異なる領域で同時に発見されていることは示唆的だ。
マルチエージェント協調パターン:Anthropicによる実践的体系化
Anthropicが公開した マルチエージェント協調パターン の解説は、理論的研究とは異なる実践的価値を持つ(
)。
5つのパターンが定義されている:
1. Generator-Verifier(生成-検証) 最もシンプルで最も広く使われるパターン。生成エージェントが出力を作り、検証エージェントが評価し、フィードバックをループさせる。コード生成、ファクトチェック、コンプライアンス検証に有効。落とし穴は「検証基準の曖昧さ」だ。基準が不明確な検証エージェントは、生成エージェントの出力をゴム印のように承認してしまう。
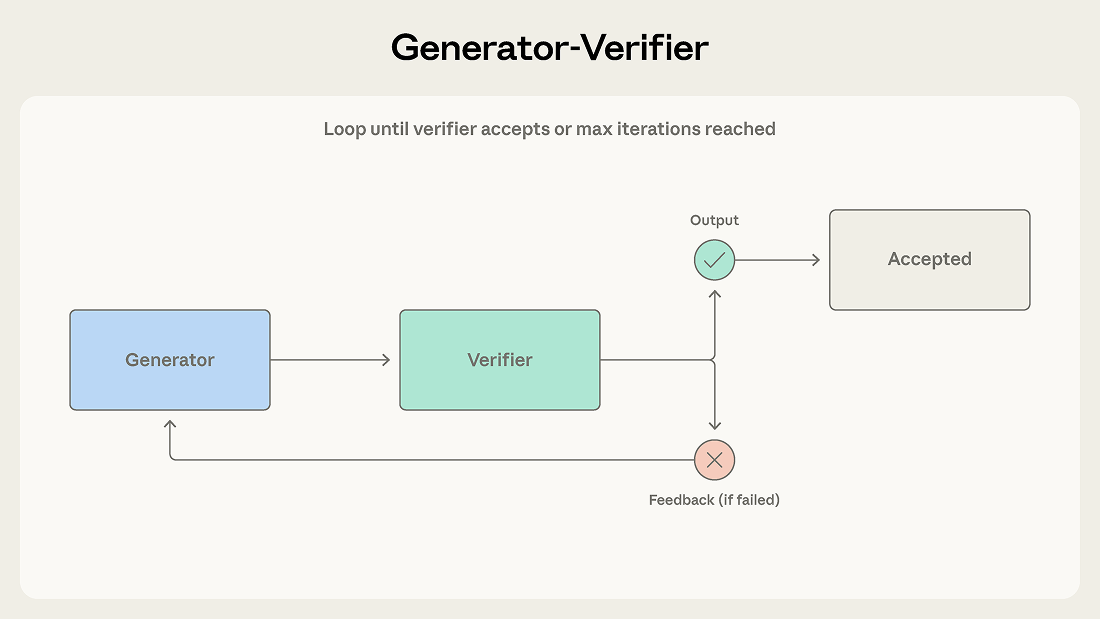 図: Generator-Verifierパターンの構造。生成→検証→フィードバックのループが品質を担保する。
図: Generator-Verifierパターンの構造。生成→検証→フィードバックのループが品質を担保する。
2. Orchestrator-Subagent(オーケストレーター-サブエージェント) 階層的パターン。リードエージェントが計画・委任・統合を担い、サブエージェントが特定タスクを処理する。Claude Codeがこのパターンを採用している。弱点は「情報ボトルネック」だ。サブエージェント間で関連する発見があっても、オーケストレーターを経由しなければ共有できない。
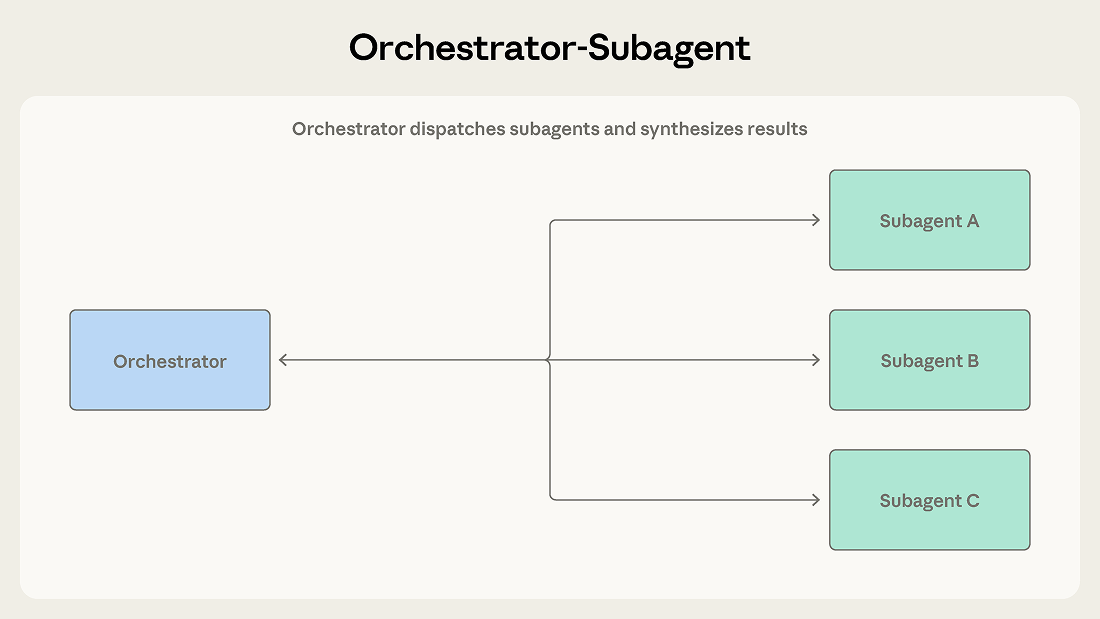 図: Orchestrator-Subagentパターン。オーケストレーターが全体像を把握しながらサブエージェントに委任する。
図: Orchestrator-Subagentパターン。オーケストレーターが全体像を把握しながらサブエージェントに委任する。
3. Agent Teams(エージェントチーム) ワーカーエージェントが長期間にわたって独立して動作し、ドメイン専門性を蓄積する。大規模コードベースの移行など、長時間の自律的作業に適する。独立性が前提条件であり、エージェント間の依存関係が生じると機能しなくなる。
4. Message Bus(メッセージバス) イベント駆動パイプライン。エージェントはイベントを発行・購読し、疎結合なエコシステムを形成する。新しいエージェントの追加が容易だが、デバッグが困難になる。
5. Shared-State(共有状態) 複数エージェントが共通の作業空間を通じて協調し、互いの発見を積み上げる。複雑な調査タスクに適するが、状態管理の複雑さが増大する。
Anthropicの推奨は明確だ:「最もシンプルなパターンから始め、どこで行き詰まるかを観察し、そこから発展させよ」。これはOmniShowの「分離後統合」戦略とも対応する。複雑な問題を最初から統合的に解こうとするのではなく、まず分解して個別に解決し、その後統合するという思想だ。
技術的潮流の統合:「最小構造・最大表現」という共通原理
4つの研究を横断すると、共通する設計哲学が浮かび上がる。
| 研究 | 問題 | 解法の原理 |
|---|---|---|
| OmniShow | 複数条件の統合 | ベースモデルへの侵襲最小化+段階的統合 |
| ELT | パラメータ効率 | 重み共有による均一構造の反復 |
| EML | 数学的普遍性 | 単一演算子の再帰的組み合わせ |
| マルチエージェント | システム設計 | 最小パターンからの段階的発展 |
EMLの発見は特に深い示唆を持つ。「すべての初等関数は単一演算子から生成できる」という事実は、複雑に見える数学的構造が実は極めて単純な基盤を持つことを示す。これはELTが「複雑な視覚表現は同一ブロックの反復で生成できる」と示したことと構造的に同型だ。
OmniShowのモデルマージングによるゼロショット汎化も同じ文脈で読める。A2VとR2Vという「単純な」能力が、適切に組み合わさることでRA2Vという「複合的な」能力を創発する。これはEMLで単純な演算子の組み合わせが複雑な関数を生成することと対応する。
業界・社会への影響と示唆
コンテンツ制作の民主化:OmniShowが示す方向性は、専門的な映像制作スキルなしに、参照画像と音声だけで高品質な動画を生成できる未来だ。ECサイト運営者が商品デモ動画を自動生成したり、個人クリエイターが音声駆動のアバター動画を制作したりすることが現実的になる。
エッジデバイスへのAI展開:ELTのパラメータ効率化は、スマートフォンやIoTデバイスへの高品質生成モデルの展開を加速する。4倍のパラメータ削減は、クラウド依存からの脱却を意味する。
AIによる数学的発見:EMLの発見は、AIが数学的構造の探索を支援できることを示す。EMLツリーを用いた勾配ベース記号回帰は、科学データから閉形式の法則を自動発見するツールとなりうる。これは物理法則の発見や材料科学への応用が期待される。
エンタープライズAIの設計論:Anthropicのマルチエージェントパターン体系化は、AI導入を検討する企業にとって実践的なガイドラインとなる。「洗練されて見えるパターンではなく、問題に合ったパターンを選べ」という警告は、過剰設計によるAIプロジェクト失敗を防ぐ上で重要だ。
まとめ・今後の展望
2026年春のAI研究は、「大きく複雑なものを作る」フェーズから「最小限の構造で最大の表現力を引き出す」フェーズへの移行を示唆している。
OmniShowは動画生成の条件制御を統合し、ELTはTransformerの効率性を根本から問い直し、EMLは連続数学の普遍的プリミティブを発見し、マルチエージェントパターンはAIシステム設計の実践知を体系化した。
今後の展望として、OmniShowのモデルマージング戦略はさらに多くのモダリティ(深度、熱画像、触覚など)への拡張が期待される。ELTの弾性推論は、リソース制約に応じた動的品質調整という新たなUXパラダイムを開く。EMLの発見は「ternary variantが定数を必要としない」という予備的結果も示しており、さらなる普遍演算子の探索が続く。マルチエージェントシステムは、共有状態パターンの成熟とともに、より複雑な知識構築タスクへの適用が進むだろう。
「単純な構成要素の反復と組み合わせから複雑な知性が生まれる」——この原理は、AIアーキテクチャ、数学的構造、そしてシステム設計の全てに貫通している。それは偶然ではなく、知性の本質的な構造を反映しているのかもしれない。
